teleport使用说明

浏览器下载网页:
只能浏览主页和少数网页,其它不能浏览,容量几百kbteleport下载项目一能完全离线看网页,7328多文件 9个JPG文件,大小134Mteleport下载项目二部分网页采集内容和项目一基本一致,但大几兆部分网页需要项目二(复制站点)才能浏览,项目一看不到图片项目二比项目一耗时多,但要全面 视频教程 YouTube  离线浏览,网站镜像,文件提取工具 遍历网站的所有链接网址,网站关键字搜索 1. 复制一个可浏览的网站,文件存放在硬盘 2.复制一个网址,包括文件结构 3.在网址搜索指定文件 包括声音,食品,背景图片,zip等等。这种方式速度快。 4.遍历网址所有链接,不会写任何文件到硬盘,此速度很快 5.指定网址下载文件,爬虫不会去其它链接 6.搜索网站关键词
离线浏览,网站镜像,文件提取工具 遍历网站的所有链接网址,网站关键字搜索 1. 复制一个可浏览的网站,文件存放在硬盘 2.复制一个网址,包括文件结构 3.在网址搜索指定文件 包括声音,食品,背景图片,zip等等。这种方式速度快。 4.遍历网址所有链接,不会写任何文件到硬盘,此速度很快 5.指定网址下载文件,爬虫不会去其它链接 6.搜索网站关键词 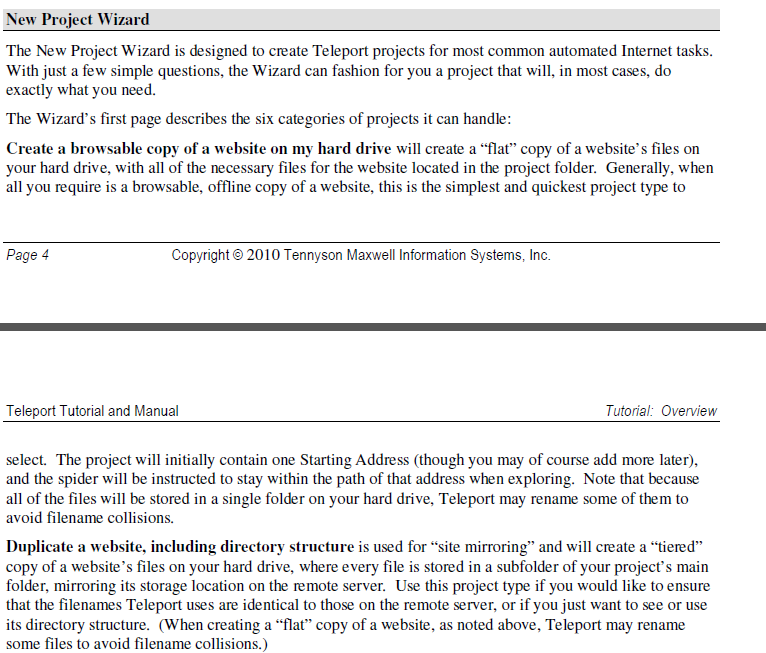
 (算法)工作原理: 1.把开始网址作为起点 2.遍历所有链接 3.对每个链接下载文件 4.重复判断 爬虫很灵活,很多参数可以自己设定。 爬虫有记忆功能,不会采集重复链接或文件
(算法)工作原理: 1.把开始网址作为起点 2.遍历所有链接 3.对每个链接下载文件 4.重复判断 爬虫很灵活,很多参数可以自己设定。 爬虫有记忆功能,不会采集重复链接或文件  项目测试 1.抓取一个网址的所有链接 选择遍历网址所有链接,不会写任何文件到硬盘,此速度很快 详细资料可以看到链接信息:
项目测试 1.抓取一个网址的所有链接 选择遍历网址所有链接,不会写任何文件到硬盘,此速度很快 详细资料可以看到链接信息: 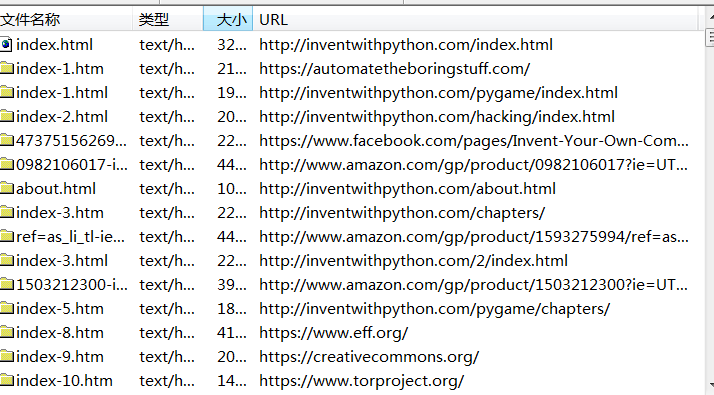 可以看到网站的树状结构
可以看到网站的树状结构 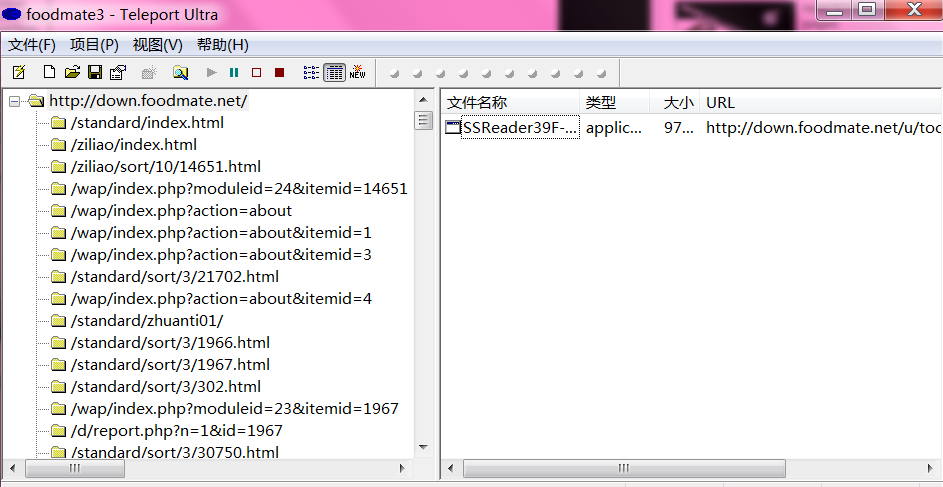 项目:选择第一项,创建一个可浏览的网站副本 打开所在文件夹,搜索index,就是主页,双击就可浏览
项目:选择第一项,创建一个可浏览的网站副本 打开所在文件夹,搜索index,就是主页,双击就可浏览 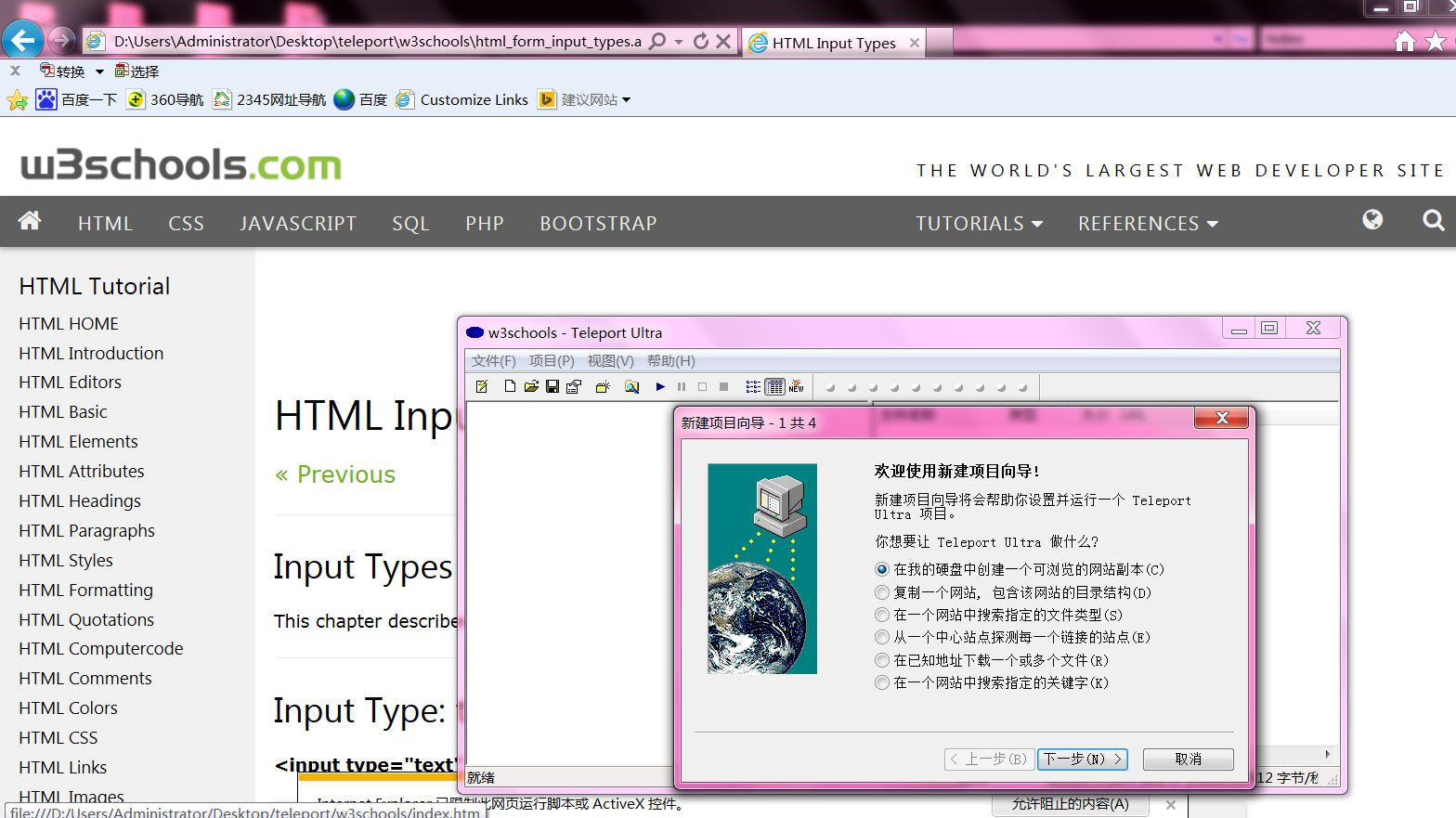 终止测试: 终止后,项目被放弃,如果再次启动项目,会重新开始 暂停测试 暂停后, 项目被放弃,如果再次启动项目,会重新开始 脚本之家项目2测试, 下载的网页不全,有点打不开 工标网不能每页采集,此软件功能有限,寻找新的软件
终止测试: 终止后,项目被放弃,如果再次启动项目,会重新开始 暂停测试 暂停后, 项目被放弃,如果再次启动项目,会重新开始 脚本之家项目2测试, 下载的网页不全,有点打不开 工标网不能每页采集,此软件功能有限,寻找新的软件
How to use Teleport Pro (Footprinting and Reconnaissance)
离线浏览,网站镜像,文件提取工具 遍历网站的所有链接网址,网站关键字搜索 1. 复制一个可浏览的网站,文件存放在硬盘 2.复制一个网址,包括文件结构 3.在网址搜索指定文件 包括声音,食品,背景图片,zip等等。这种方式速度快。 4.遍历网址所有链接,不会写任何文件到硬盘,此速度很快 5.指定网址下载文件,爬虫不会去其它链接 6.搜索网站关键词 (算法)工作原理: 1.把开始网址作为起点 2.遍历所有链接 3.对每个链接下载文件 4.重复判断 爬虫很灵活,很多参数可以自己设定。 爬虫有记忆功能,不会采集重复链接或文件 项目测试 1.抓取一个网址的所有链接 选择遍历网址所有链接,不会写任何文件到硬盘,此速度很快 详细资料可以看到链接信息: 可以看到网站的树状结构 项目:选择第一项,创建一个可浏览的网站副本 打开所在文件夹,搜索index,就是主页,双击就可浏览 终止测试: 终止后,项目被放弃,如果再次启动项目,会重新开始 暂停测试 暂停后, 项目被放弃,如果再次启动项目,会重新开始 脚本之家项目2测试, 下载的网页不全,有点打不开 工标网不能每页采集,此软件功能有限,寻找新的软件